
开源版SearchGPT来了,两张3090就可复现,卓绝Perplexity付费版

VSA团队 投稿
量子位 | 公众号 QbitAIOpenAI推出SearchGPT没几天,开源版块也来了。
港汉文MMLab、上海AI Lab、腾讯团队简便杀青了Vision Search Assistant,模子运筹帷幄概略,独一两张RTX3090就可复现。

Vision Search Assistant(VSA)以视觉讲话模子(VLM)为基础,阴私地将Web搜索武艺融入其中,让VLM里面的学问得到及时更新,使其愈加天真和智能。
当今,VSA一经针对通用图像进行了实验,可视化和量化成果邃密。但不同类别的图像各具特质,还不错针对不同种类的图像(比如表格、医学等)构建出更为特定的VSA应用。
更令东谈主立志的是,VSA的后劲并不仅限于图像处理。还有更广袤的可探索空间,比如视频、3D模子和声息等边界,期待能将多模态计划推向新的高度。

让VLM处理未见过的图像和新观点
大型讲话模子(LLM)的出现让东谈主类不错愚弄模子的高大零样本问答武艺来获取生分学问。
在此基础上,检索增强生成(RAG)等时间进一步提高了LLM在学问密集型、绽放域问答任务中的证据。然则,VLM在面临未见过的图像和新观点时,它们经常弗成愚弄好来自互联网的最新多模态学问。
现存的 Web Agent主要依赖于对用户问题的检索,并回来检索复返的HTML文本实践,因此它们在处理触及图像或其他视觉实践的任务时存在显著的局限性,即视觉信息被忽视或处理不充分。
为了处理这一问题,团队忽视了Vision Search Assistant。Vision Search Assistant以VLM模子为基础,大略回答干系未见过的图像或新观点的问题,其步履访佛东谈主类在互联网上进行搜索并处理问题的过程,包括:
意会查询决定应该柔软图像中的哪些对象并预计对象之间的干系性逐对象生成查询文本根据查询文本和预计出的干系性分析搜索引擎复返的实践判断获取的视觉和文本信息是否足以生成谜底,或者它应该迭代和转变上述过程调处检索成果,回答用户的问题视觉实践描摹视觉实践描摹模块被用来索求图像中对象级的描摹和对象之间的干系性,其历程如下图所示。
首先愚弄绽放域的检测模子来获取值得柔软的图像区域。紧接着对每一个检测到的区域,使用VLM获取对象级的文本描摹。
终末,为了更全面地抒发视觉实践,愚弄VLM进一步关联不同的视觉区域以获取不同对象的更精准描摹。

具体地,令用户输入图片为,用户的问题为。可通过一个绽放域的检测模子获取个感兴趣兴趣的区域:
然后愚弄预历练的VLM模子分散描摹这个区域的视觉实践:
为了让不同区域的信息关联起来,提高描摹的精度,可将区域与其它区域的描摹拼接,让VLM对区域的描摹进行矫正:
至此,从用户输入获取了与之高度干系的个视觉区域的精准描摹。
Web学问搜索:“搜索链”Web学问搜索的中枢是名为“搜索链”的迭代算法,旨在获取干系视觉描摹的详细性的Web学问,其历程如下图所示。

在Vision Search Assistant中愚弄LLM来生成与谜底干系的子问题,这一LLM被称为“Planing Agent”。搜索引擎复返的页面会被雷同的LLM分析、罗致和回来,被称为“Searching Agent”。通过这种状态,不错获取与视觉实践干系的Web学问。
具体地,由于搜索是对每个区域的视觉实践描摹分散进行的,因此以区域为例,并不详这个上标,即。该模块中使用消除个LLM模子构建方案智能体(Planning Agent)和搜索智能体(Searching Agent)。方案智能体收尾通盘搜索链的历程,搜索智能体与搜索引擎交互,筛选、回来网页信息。
以第一轮迭代为例,方案智能体将问题拆分红个搜索子问题并交由搜索智能体处理。搜索智能体会将每一个委派搜索引擎,得到页面集会。搜索引擎会阅读页面选录并罗致与问题最干系的页面集会(下标集为),具体智商如下:
关于这些被选中的页面,搜索智能体会放心阅读其实践,并进行回来:
最终,系数个子问题的回来运送给方案智能体,方案智能体回来得到第一轮迭代后的Web学问:
重叠进行上述迭代过程次,或是方案智能体觉得现时的Web学问已足矣回答原问题时,搜索链住手,得到最终的Web学问。
协同生成最终基于原始图像、视觉描摹、Web学问,愚弄VLM回答用户的问题,其历程如下图所示。具体而言,最终的回答为:

实验成果绽放集问答可视化对比
下图中比较了新事件(前两行)和新图像(后两行)的绽放集问答成果。
将Vision Search Assistant和Qwen2-VL-72B以及InternVL2-76B进行了比较,不难发现,Vision Search Assistant 擅永生成更新、更准确、更放心的成果。
举例,在第一个样例中,Vision Search Assistant对2024年Tesla公司的情况进行了回来,而Qwen2-VL局限于2023年的信息,InternVL2明确暗示无法提供该公司的及时情况。

绽放集问答评估
在绽放集问答评估中,悉数通过10位东谈主类民众进行了比较评估,评估实践触及7月15日至9月25日历间从头闻中采集的100个图文对,涵盖新颖图像和事件的系数边界。
东谈主类民众从实在性、干系性和赈济性三个关节维度进行了评估。
如下图所示,与Perplexity.ai Pro和GPT-4-Web比拟,Vision Search Assistant在系数三个维度上齐证据出色。
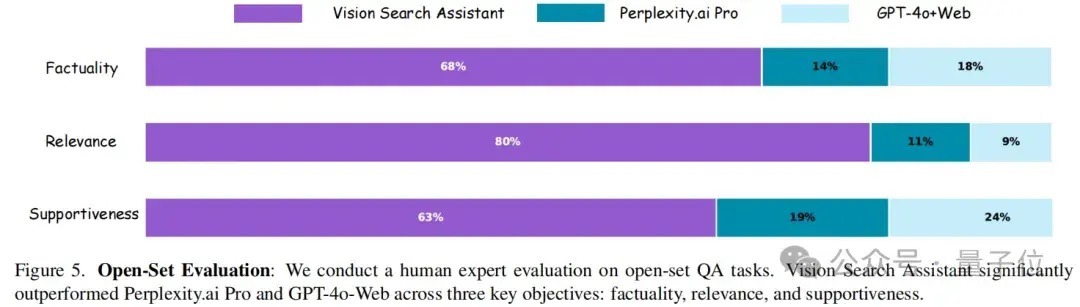
事实性:Vision Search Assistant得分为68%,优于Perplexity.ai Pro(14%)和 GPT-4-Web(18%)。这一权贵率先标明,Vision Search Assistant 永久提供更准确、更基于事实的谜底。干系性:Vision Search Assistant 的干系性得分为80%,在提供高度干系的谜底方面证据出权贵上风。比拟之下,Perplexity.ai Pro和GPT-4-Web分散达到11%和9%,显浮现在保执集聚搜索时效性方面存在权贵差距。赈济性:Vision Search Assistant在为其反应提供充分把柄和事理方面也优于其他模子,赈济性得分为63%。Perplexity.ai Pro和GPT-4-Web分散以19%和24%的得分逾期。这些成果突显了Vision Search Assistant 在绽放集任务中的超卓证据,尽头是在提供全面、干系且得到邃密赈济的谜底方面,使其成为处理新图像和事件的灵验智商。阻滞集问答评估
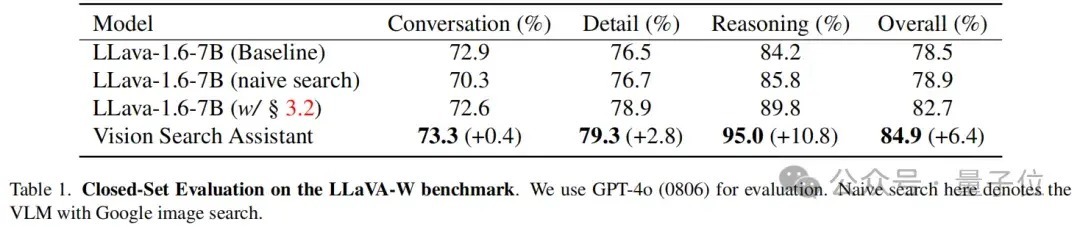
在LLaVA W基准进行闭集评估,其中包含60个问题,触及VLM在田园的对话、细节和推理武艺。
使用GPT-4o(0806)模子进行评估,使用LLaVA-1.6-7B当作基线模子,该模子在两种模式下进行了评估:范例模式和使用概略Google图片搜索组件的“朴素搜索”模式。
此外还评估了LLaVA-1.6-7B的增强版块,该版块配备搜索链模块。
如下表所示,Vision Search Assistant在系数类别中均证据出最强的性能。具体而言,它在对话类别中获取了73.3%的得分,与LLaVA模子比拟略有擢升,擢升幅度为+0.4%。在细节类别中,Vision Search Assistant以79.3%的得分脱颖而出,比证据最好的LLaVA变体向上 +2.8%。
在推理方面,VSA智商比证据最好的LLaVA模子向上+10.8%。这标明Vision Search Assistant对视觉和文本搜索的高档集成极地面增强了其推理武艺。
Vision Search Assistant的举座性能为84.9%,比基线模子提高+6.4%。这标明Vision Search Assistant在对话和推理任务中齐证据出色,使其在田园问答武艺方面具有显著上风。
论文:https://arxiv.org/abs/2410.21220
主页:https://cnzzx.github.io/VSA/代码:https://github.com/cnzzx/VSA— 完 —
量子位 QbitAI · 头条号签约
柔软咱们,第一时辰获知前沿科技动态